1. Les outils statistiques en python
Lorsque vous souhaitez effectuer une analyse statistique, le langage Python vous offre une multitude d'outils et bibliothèques pour vous aider à effectuer des calculs statistiques, des visualisations et des tests. Voici quelques-uns des outils et bibliothèques les plus couramment utilisés en analyse statistique avec Python :
- NumPy : NumPy est une bibliothèque fondamentale pour la manipulation de tableaux multidimensionnels en Python. Il offre des fonctions pour effectuer des calculs numériques et statistiques, y compris des moyennes, des médianes, des écarts types, des corrélations, etc.
- pandas : pandas est une bibliothèque permettant de manipuler et d'analyser des données tabulaires. Elle offre des structures de données telles que les DataFrames et les Series, ainsi que des fonctionnalités pour effectuer des opérations de groupage, de filtrage, de fusion, et bien d'autres encore.
- Matplotlib : Matplotlib est une bibliothèque de visualisation de données qui permet de créer une grande variété de graphiques, notamment des histogrammes, des diagrammes à barres, des diagrammes de dispersion, des graphiques en boîte, etc.
- Seaborn : Seaborn est une bibliothèque de visualisation de données basée sur Matplotlib, qui simplifie la création de graphiques statistiques informatifs et esthétiques. Elle est particulièrement utile pour les tracés de données complexes et les visualisations en lien avec les statistiques.
- SciPy : SciPy est une bibliothèque qui étend les fonctionnalités de NumPy en proposant des outils spécifiques pour l'analyse statistique et scientifique, tels que des tests statistiques, des optimisations, des interpolations, etc.
- statsmodels : statsmodels est une bibliothèque qui offre des fonctionnalités pour l'estimation de modèles statistiques, notamment la régression linéaire, la régression logistique, l'ANOVA, etc.
- scikit-learn : scikit-learn est une bibliothèque d'apprentissage automatique (machine learning) qui propose des outils pour la classification, la régression, le regroupement, la réduction de dimension, etc. Elle inclut également des modules pour évaluer les performances des modèles.
- patsy : patsy est une bibliothèque permettant de spécifier des modèles statistiques en utilisant une syntaxe simple, ce qui facilite la création de modèles pour statsmodels et d'autres bibliothèques statistiques.
- Jupyter Notebook : Jupyter Notebook est un environnement interactif qui permet de créer et d'exécuter du code Python de manière itérative. Il est très utile pour explorer et documenter vos analyses statistiques étape par étape.
2. A propos de la bibliothèque numpy
2.1 la bibliothèque numpy
NumPy (Numérique Python) est l'une des bibliothèques les plus fondamentales et essentielles pour le calcul scientifique et numérique en Python. Elle fournit des structures de données et des fonctions pour travailler avec des tableaux multidimensionnels (appelés "ndarrays") et effectuer des opérations mathématiques sur ces tableaux. Voici quelques aspects importants de la bibliothèque NumPy :
- ndarray : L'élément central de NumPy est l'objet "ndarray". Il s'agit d'un tableau multidimensionnel qui peut contenir des données de type homogène (par exemple, des nombres entiers, des nombres flottants, etc.). Les tableaux NumPy sont plus efficaces que les listes Python standard pour le stockage et la manipulation de données numériques.
- Opérations vectorielles et mathématiques : NumPy offre un large éventail d'opérations mathématiques et statistiques qui peuvent être appliquées directement aux tableaux. Cela permet d'effectuer des calculs vectoriels et matriciels de manière efficace et concise. Par exemple, vous pouvez effectuer des opérations
- Indexation et découpage : Vous pouvez accéder aux éléments d'un tableau NumPy en utilisant une syntaxe similaire à celle des listes Python, mais avec des fonctionnalités de découpage (slicing) plus pu
- Fonctions pour la génération de données : NumPy propose diverses fonctions pour générer des données aléatoires, telles que des nombres aléatoires, des échantillons aléatoires à partir de distributions statistiques, etc. Cela est utile pour la simulation et la génération de données de test.
- Intégration avec d'autres bibliothèques : NumPy est souvent utilisé en combinaison avec d'autres bibliothèques scientifiques telles que SciPy (pour les calculs scientifiques avancés), Matplotlib (pour la visualisation de données) et pandas (pour la manipulation de données tabulaires). Il joue un rôle central dans l'écosystème des bibliothèques scientifiques Python.
- Performance : Les opérations sur les tableaux NumPy sont généralement très rapides, car elles sont implémentées en C sous-jacent. Cela rend NumPy adapté aux calculs numériques intensifs et au traitement de grands ensembles de données.
- Communauté active : NumPy est maintenu par une communauté active de développeurs et est largement utilisé dans la recherche scientifique, l'analyse de données, l'apprentissage automatique et d'autres domaines.
2.2 Installation et usage de la bibliothèque numpy
Installation
Rien de plus simple, il suffit de lancer l'invite de commande et saisir le code :
|
1 |
pip install numpy |
Usage de numpy
Pour utiliser NumPy, vous devez l'importer dans votre script Python en utilisant la commande:
|
1 |
import numpy as np |
puis vous pouvez accéder à ses fonctions et objets en utilisant le préfixe np.
Exemple
|
1 2 3 4 |
# créer un tableau NumPy nommé Tab à partir d'une liste L , Tab = np.array(L) # Calculer la moyenne du tableau Tab np.mean(Tab) |
3. Les méthodes de numpy destinées à l'analyse statistique
NumPy met à disposition un ensemble complet de méthodes couramment employées en analyse statistique, permettant ainsi le calcul de statistiques descriptives, la réalisation d'opérations élémentaires sur des ensembles de données, ainsi que le calcul des différents paramètres statistiques. Voici quelques-unes des méthodes essentielles à utiliser lors d'analyses statistiques avec NumPy :
3.1 Moyenne et Médiane
- np.mean(arr): Calcule la moyenne des éléments du tableau.
- np.median(arr): Calcule la médiane des éléments du tableau.
3.2 Écart type, Variance et Quantiles
- np.std(arr): Calcule l'écart type des éléments du tableau.
- np.var(arr): Calcule la variance des éléments du tableau.
- np.percentile(arr, q): Calcule le quantile q (en pourcentage) des éléments du tableau.
3.3 Minimum et Maximum
- np.min(arr): Retourne la valeur minimale du tableau.
- np.max(arr): Retourne la valeur maximale du tableau.
3.4 Somme et Produit
- np.sum(arr): Calcule la somme des éléments du tableau.
- np.prod(arr): Calcule le produit des éléments du tableau.
3.5 Corrélation et Histogramme
- np.corrcoef(arr1, arr2): Calcule le coefficient de corrélation entre deux tableaux.
- np.histogram(arr, bins): Calcule un histogramme à partir du tableau avec les bins spécifiés.
3.6 Résumé statistique
- np.describe(arr): Fournit un résumé statistique des éléments du tableau, incluant la moyenne, l'écart type, le minimum, le maximum, etc.
3.7 Opérations logiques
- np.logical_and(arr1, arr2): Effectue un ET logique élément par élément entre deux tableaux booléens.
- np.logical_or(arr1, arr2): Effectue un OU logique élément par élément entre deux tableaux booléens.
3.8 Tests statistiques
NumPy ne propose pas directement de fonctions pour effectuer des tests statistiques, mais vous pouvez utiliser SciPy, qui s'appuie sur NumPy, pour effectuer une gamme complète de tests statistiques comme le test t, le test de chi-carré, l'ANOVA, etc.
3.9 Réarrangement des données
- np.sort(arr): Trie les éléments du tableau par ordre croissant.
- np.argsort(arr): Retourne les indices qui trieraient le tableau.
- np.unique(arr): Retourne les valeurs uniques du tableau.
4. Exemples d'usages sur un échantillon de données
Nous allons voir dans ce paragraphe un exemple simple d'utilisation de NumPy pour analyser un échantillon de données sur les âges d'élèves d'une classe de terminale. Dans cet exemple, nous allons calculer la moyenne, la médiane, l'écart type et créer un histogramme, courbe pour visualiser la distribution des âges.
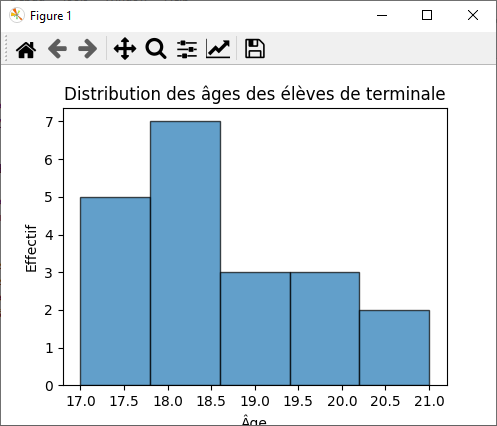
4.1 Histogramme des effectifs
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import numpy as np import matplotlib.pyplot as plt # Échantillon d'âges d'élèves de terminale ages = np.array([17, 20, 17, 18, 18, 17, 18, 19, 21, 18, 18, 17, 21, 18, 19, 17, 18, 20, 20, 19]) # Calcul de la moyenne et de la médiane moyenne_age = np.mean(ages) median_age = np.median(ages) # clacul de la variance var_age = np.var(ages) # Calcul de l'écart type ecart_type_age = np.std(ages) # Affichage des statistiques print(f'Moyenne des âges : {moyenne_age}') print(f'Médiane des âges : {median_age}') print(f'Variance des âges : {var_age}') print(f'Écart type des âges : {ecart_type_age}') # Création d'un histogramme pour visualiser la distribution des âges plt.hist(ages, bins=5, edgecolor='k', alpha=0.7) plt.xlabel('Âge') plt.ylabel('Effectif') plt.title('Distribution des âges des élèves de terminale') plt.show() """ Moyenne des âges : 18.5 Médiane des âges : 18.0 Variance des âges : 1.65 Écart type des âges : 1.284523257866513 """ |
- Nous créons un tableau NumPy appelé ages : pour stocker l'échantillon d'âges des élèves de terminale.
- Nous utilisons les fonctions np.mean() et np.median() : pour calculer respectivement la moyenne et la médiane des âges.
- Nous utilisons np.std() : pour calculer l'écart type des âges.
- Enfin, nous créons un histogramme à l'aide de Matplotlib : pour visualiser la distribution des âges.
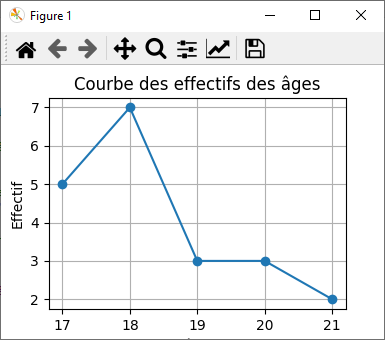
4.2 Courbe des effectifs
Pour tracer la courbe des effectifs des âges, vous pouvez utiliser un diagramme linéaire plutôt qu'un histogramme. Voici comment vous pouvez le faire en utilisant Matplotlib :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import numpy as np import matplotlib.pyplot as plt # Échantillon d'âges ages = np.array([17, 18, 17, 18, 18, 17, 17, 19, 18, 17, 18, 17, 18, 18, 19, 17, 18, 18, 18, 19]) # Comptez les effectifs pour chaque âge unique_ages, counts = np.unique(ages, return_counts=True) # Créez un diagramme linéaire des effectifs plt.plot(unique_ages, counts, marker='o', linestyle='-') # Définissez des étiquettes et un titre plt.xlabel('Âge') plt.ylabel('Effectif') plt.title('Courbe des effectifs des âges') # Affichez la courbe plt.grid(True) # Ajoutez une grille plt.show() |
Explication du code :
- np.unique(ages, return_counts=True) : pour obtenir les âges uniques et leurs effectifs correspondants.
- plt.plot() : pour créer un diagramme linéaire des effectifs. Nous utilisons marker='o' pour afficher des points sur la ligne pour chaque âge et linestyle='-' pour utiliser une ligne solide pour relier les points.
- (xlabel et ylabel) et (title) : sont définis pour améliorer la lisibilité du graphique.
- plt.grid(True) : ajoute une grille au graphique.
- plt.show() : affiche la courbe des effectifs.
Ce code générera un graphique montrant la courbe des effectifs des âges, où l'axe des x représente les âges uniques et l'axe des y représente le nombre d'élèves ayant chaque âge:
Younes Derfoufi
CRMEF OUJDA


