1. A propos de la bibliothèque scikit-learn
scikit-learn est l'une des bibliothèques Python les plus populaires pour l'apprentissage automatique (machine learning). Elle offre un large éventail d'algorithmes d'apprentissage supervisé et non supervisé, ainsi que des outils pour la préparation des données, la sélection de modèle, l'évaluation de performances et bien plus encore.
2. Principales fonctionnalités et caractéristiques
- Facilité d'utilisation : scikit-learn est conçu pour être simple à utiliser et à comprendre. Sa syntaxe claire et cohérente permet aux utilisateurs de rapidement mettre en œuvre des algorithmes d'apprentissage automatique sans avoir besoin de connaissances avancées en mathématiques ou en informatique.
- Large sélection d'algorithmes : scikit-learn offre une gamme complète d'algorithmes pour les tâches d'apprentissage supervisé (classification, régression) et non supervisé (clustering, réduction de dimensionnalité). Cela inclut des méthodes populaires telles que les k-plus proches voisins, les arbres de décision, les machines à vecteurs de support (SVM), les forêts aléatoires, la régression linéaire, etc.
- Intégration avec NumPy et SciPy : scikit-learn est construit sur NumPy et SciPy, deux bibliothèques fondamentales pour le calcul scientifique en Python. Cela lui permet de tirer parti de leurs structures de données et de leurs fonctions pour une manipulation efficace des données et une implémentation optimisée des algorithmes.
- Outils de prétraitement des données : scikit-learn propose une variété d'outils pour la préparation des données, y compris le traitement des valeurs manquantes, le codage des variables catégorielles, la normalisation des caractéristiques, etc. Ces outils sont essentiels pour préparer les données avant de les utiliser pour l'apprentissage automatique.
- Évaluation des modèles : scikit-learn fournit des métriques d'évaluation de modèle telles que la précision, le rappel, la F1-score, l'aire sous la courbe ROC, etc. Ces métriques permettent d'évaluer les performances des modèles sur des ensembles de données de test et d'effectuer des comparaisons entre différents modèles.
- Validation croisée : scikit-learn propose des techniques de validation croisée telles que la validation croisée k-fold, qui permettent d'estimer la performance d'un modèle de manière robuste en utilisant l'ensemble des données disponibles.
- Sélection de modèle : scikit-learn offre des outils pour la sélection de modèle, y compris la recherche sur grille (grid search) et la recherche aléatoire (random search), qui permettent d'identifier les hyperparamètres optimaux pour un modèle donné.
- Extensibilité : scikit-learn est conçu pour être extensible, ce qui signifie que vous pouvez facilement ajouter de nouveaux algorithmes ou étendre les fonctionnalités existantes en créant vos propres classes et fonctions.
- Documentation exhaustive : Scikit-learn est bien documenté avec des exemples détaillés et une documentation complète. Cela en fait une ressource précieuse pour les personnes qui souhaitent apprendre les bases de l'apprentissage automatique ou explorer de nouveaux concepts.
- Support de la communauté : Scikit-learn bénéficie d'une communauté active qui contribue au développement de la bibliothèque et fournit un support via des forums en ligne, des listes de diffusion, et des canaux de communication sur les réseaux sociaux.
3. Liste des principales sous bibliothèque de scikit-learn
cikit-learn est composé de plusieurs sous-bibliothèques, chacune offrant des fonctionnalités spécifiques pour différentes tâches d'apprentissage automatique. Voici une liste des principales sous-bibliothèques de scikit-learn:
- sklearn.datasets : Cette sous-bibliothèque contient des jeux de données de démonstration et des utilitaires pour charger des ensembles de données externes. Elle offre des fonctions pour charger des ensembles de données populaires tels que Iris, Boston Housing, et digits.
- sklearn.preprocessing : Utilisé pour effectuer des prétraitements sur les données avant de les utiliser pour l'apprentissage automatique. Il offre des fonctionnalités telles que la normalisation, la binarisation, l'imputation des valeurs manquantes, etc.
- sklearn.feature_extraction : Contient des utilitaires pour extraire des caractéristiques à partir de données brutes. Cela inclut la transformation de texte en vecteurs numériques à l'aide de méthodes telles que TF-IDF et le sac de mots.
- sklearn.feature_selection : Cette sous-bibliothèque fournit des outils pour sélectionner les caractéristiques les plus pertinentes pour l'apprentissage automatique. Elle comprend des méthodes de sélection basées sur les scores, la récursivité, etc.
- sklearn.model_selection : Utilisé pour diviser les données en ensembles d'entraînement et de test, ainsi que pour effectuer une validation croisée afin d'évaluer les performances des modèles.
- sklearn.metrics : Contient une large gamme de métriques d'évaluation de modèle telles que l'accuracy, la précision, le rappel, le F1-score, l'aire sous la courbe ROC, etc.
- sklearn.linear_model : Fournit des modèles de régression linéaire, de régression logistique et d'autres méthodes de régression.
- sklearn.svm : Contient des implémentations des machines à vecteurs de support (SVM) pour la classification et la régression.
- sklearn.tree : Contient des implémentations d'arbres de décision pour la classification et la régression.
- sklearn.ensemble : Cette sous-bibliothèque fournit des méthodes d'ensemble telles que les forêts aléatoires, les méthodes de boosting (AdaBoost, Gradient Boosting), etc.
- sklearn.cluster : Utilisé pour effectuer le clustering des données à l'aide d'algorithmes tels que KMeans, DBSCAN, etc.
- sklearn.naive_bayes : Contient des implémentations de classificateurs naïfs de Bayes, tels que MultinomialNB et GaussianNB.
- sklearn.neighbors : Fournit des méthodes pour le calcul des voisins les plus proches, utilisé dans des algorithmes tels que KNeighborsClassifier et KNeighborsRegressor.
- sklearn.neural_network : Contient des implémentations de réseaux de neurones pour la classification, la régression et le clustering.
- sklearn.pipeline : Permet de chaîner plusieurs étapes de traitement des données et de modélisation en une seule étape, facilitant ainsi le déploiement et la réutilisation des pipelines d'apprentissage automatique.
4. Exemples d'usages en machine learning
4.1 Exemple avec le modèle linéaire
sklearn.linear_model est un module de la bibliothèque scikit-learn qui fournit des outils pour la modélisation des données à l'aide de techniques de régression linéaire, ainsi que d'autres méthodes linéaires pour l'apprentissage supervisé.
Voici quelques fonctionnalités que peut offrir la bibliothèque sklearn.linear_model:
- Régression linéaire
- Régression logistique
- Régressions robustes
- Sélection de modèle
Nous allons donner ici un exemple de modèle linéaire avec la classe LinearRegression permettant de prédire le prix d'une maison selon sa superficie.
from sklearn.linear_model import LinearRegression
# Données d'entraînement : superficie de la maison (en mètres carrés)
X_train = [[90], [150], [185], [230]] # Superficie
# Labels correspondants : prix de la maison
y_train = [150000, 200000, 250000, 300000] # Prix en dollars
# Création du modèle
model = LinearRegression()
# Entraînement du modèle sur les données
model.fit(X_train, y_train)
# Données de test
X_test = [[50], [160], [1600]] # Superficie
# Prédiction
predictions = model.predict(X_test)
# Affichage des prédictions
for i, prediction in enumerate(predictions):
print("Pour une superficie de {} m², le prix prédit est \
de ${}".format(X_test[i][0], round(prediction, 2)))
"""
output:
Pour une superficie de 50 m², le prix prédit est de $101402.99
Pour une superficie de 160 m², le prix prédit est de $220925.37
Pour une superficie de 1600 m², le prix prédit est de $1785582.09
"""
Interprétation des résultats:
- Une valeur de 50 m2 : proche de la moitiée des superficies fournies en données d'entrainement le système propose une valeur proche de la moitié des moyennes des prix fournis en données d'entrainement.
- Une valeur de 160 m2 : proche de la moyenne des superficies fournies en données d'entrainement le système propose une valeur proche de la moyenne des prix fournis en données d'entrainement.
- Une valeur de 160 m2 : proche de 10 fois la moyenne des superficies fournies en données d'entrainement le système propose une valeur proche de 10 fois la moyenne des prix fournis en données d'entrainement.
4.2 Exemples d'usages avec sklearn.neighbors
sklearn.neighbors est un module de la bibliothèque scikit-learn qui fournit des outils pour le travail avec les méthodes basées sur les voisins les plus proches. Ces méthodes sont principalement utilisées pour la classification et la régression, basées sur la similarité des données. Nous allons traiter un exemple simple basé sur les moyennes des élèves en mathématiques en introduisant des données d'entrainement affectant des labels : "Aime les mathématiques" et "N'aime pas les mathématiques" selon les moyennes obtenues en mathématiques:
from sklearn.neighbors import KNeighborsClassifier
# Données d'entraînement : moyenne en mathématiques et aime les mathématiques ou non
X_train = [[7], [15], [17], [9]] # Moyenne en mathématiques (notée sur 20)
# Labels correspondants : 0 pour n'aime pas, 1 pour aime
y_train = [0, 1, 1, 0]
# Création du modèle
model = KNeighborsClassifier(n_neighbors=1)
# Entraînement du modèle sur les données
model.fit(X_train, y_train)
# Données de test
X_test = [[12], [18], [7]] # Moyenne en mathématiques (notée sur 20)
# Prédiction
predictions = model.predict(X_test)
# Affichage des prédictions
for i, prediction in enumerate(predictions):
print("Personne {} : {}".format(i+1, "Aime" if prediction == 1 else "N'aime pas"))
"""
output:
Personne 1 : Aime
Personne 2 : Aime
Personne 3 : N'aime pas
"""
4.3 Exemple d'usage de scikit-learn avec sklearn.cluster
Le module sklearn.cluster de scikit-learn offre plusieurs classes pour effectuer des tâches de clustering. Voici quelques-unes des classes les plus couramment utilisées dans ce module:
- KMeans : Divise les données en k clusters en minimisant la variance intra-cluster.
- AgglomerativeClustering : Construit une hiérarchie de clusters en fusionnant progressivement les clusters voisins.
- DBSCAN : Identifie les clusters de forme arbitraire dans des données contenant du bruit.
- MeanShift : Algorithme de clustering non paramétrique basé sur la densité.
- Birch : Efficace pour le clustering de grands ensembles de données.
- AffinityPropagation : Identifie automatiquement des exemplaires parmi les données et les utilise pour propager des "messages" entre les points jusqu'à convergence.
- MiniBatchKMeans : Version de K-means utilisant des mini-lots pour accélérer le calcul sur de grands ensembles de données.
- OPTICS : Extension de DBSCAN pour construire une représentation hiérarchique des clusters.
L'algorithme k-means est un algorithme de clustering largement utilisé en apprentissage non supervisé (unsupervised learning) pour partitionner un ensemble de données en un nombre prédéfini de groupes (appelés clusters). L'objectif principal du k-means est de diviser les données en clusters de telle sorte que les points à l'intérieur d'un même cluster soient similaires les uns aux autres, tandis que les points dans des clusters différents soient aussi différents que possible.
Un algorithme k-means fonctionne selon le mecanisme suivant:
- Initialisation des centroïdes : Tout d'abord, l'algorithme sélectionne aléatoirement k points à partir des données comme les centroïdes initiaux des clusters. Ces points peuvent être choisis au hasard ou selon une méthode spécifique comme la méthode Forgy ou la méthode de partitionnement aléatoire.
- Affectation des points aux clusters : Ensuite, chaque point de données est affecté au cluster dont le centroïde est le plus proche en termes de distance. La distance la plus couramment utilisée est la distance euclidienne, bien que d'autres mesures de distance puissent également être utilisées.
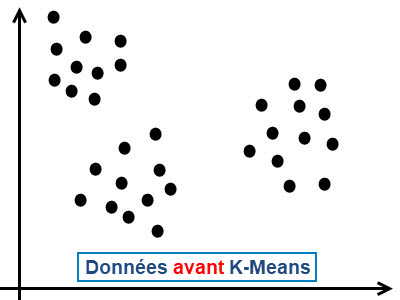 |
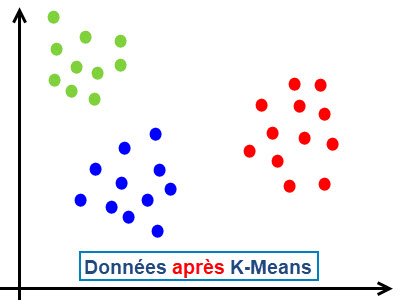 |
Exemple d'usage de sklearn.cluster avec K-Means
KMeans : Cette classe implémente l'algorithme K-means, qui est l'un des algorithmes de clustering les plus populaires. Il divise un ensemble de données en k clusters en minimisant la variance intra-cluster.
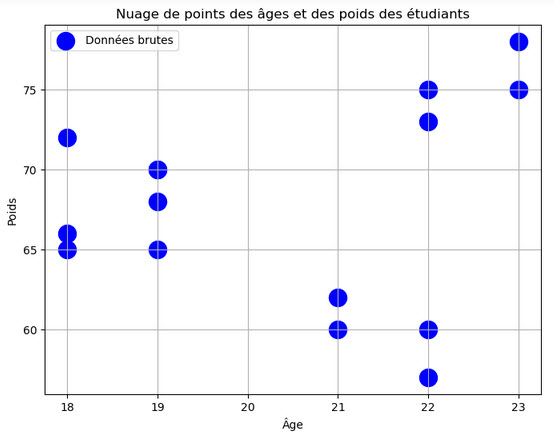
Nous allons traiter à titre d'exemple un ensemble de données constitué d'une liste de tuples (age , poids) formés d'ages et de poids d'un groupe d'étudiants:
studentsData = np.array([(19, 70), (18, 65), (21, 62), (18, 72), (18, 66),
(19, 65), (19, 70), (22, 57), (22, 73), (19, 68),
(23, 75), (23, 78), (22, 60), (22 , 75), (21, 60)])
afin de pouvoir implémenter l'algorithme de clustering pour ces données, nous devons suivre les étapes suivantes:
- Extraire les âges et les poids des étudiants
- Créer un nuage de points pour visualiser les données
- Créer le modèle K-means avec un nombre clusters à titre d'exemple 3
- Obtenir les labels des clusters pour chaque point
- Assigner des couleurs spécifiques à chaque cluster
- Visualiser les clusters obtenus avec des couleurs différentes
# ( 1 ) Extraire les âges et les poids des étudiants ages = studentsData[:, 0] weights = studentsData[:, 1]
# ( 2 ) Créer un nuage de points pour visualiser les données
plt.figure(figsize=(8, 6))
plt.scatter(ages, weights, c='blue', marker='o', label='Données brutes' , s=250)
plt.title('Nuage de points des âges et des poids des étudiants')
plt.xlabel('Âge')
plt.ylabel('Poids')
plt.legend()
plt.grid(True)
plt.show()
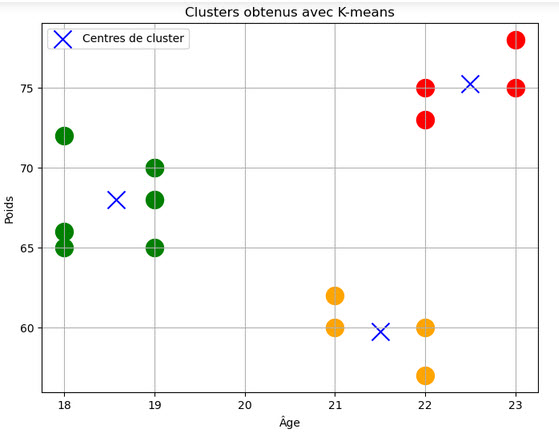
# ( 3 ) Créer et ajuster le modèle K-means avec 3 clusters kmeans = KMeans(n_clusters=3, n_init=10) kmeans.fit(studentsData)
# ( 4 ) Obtenir les centres des clusters centroids = kmeans.cluster_centers_
# ( 5 ) Obtenir les labels des clusters pour chaque point labels = kmeans.labels_
# ( 6 ) Assigner des couleurs spécifiques à chaque cluster colors = ['red', 'green', 'orange']
# ( 7 ) Visualiser les clusters obtenus avec des couleurs différentes
plt.figure(figsize=(8, 6))
for i in range(len(studentsData)):
plt.scatter(studentsData[i][0], studentsData[i][1], c=colors[labels[i]], marker='o', s=250)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', s=250, c='blue', label='Centres de cluster')
plt.title('Clusters obtenus avec K-means')
plt.xlabel('Âge')
plt.ylabel('Poids')
plt.legend()
plt.grid(True)
plt.show()
Code complet
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import warnings
# Définir les données
studentsData = np.array([(19, 70), (18, 65), (21, 62), (18, 72), (18, 66), (19, 65),
(19, 70), (22, 57), (22, 73), (19, 68), (23, 75), (23, 78),
(22, 60), (22 , 75), (21, 60)])
# ( 1 ) Extraire les âges et les poids des étudiants
ages = studentsData[:, 0]
weights = studentsData[:, 1]
# Ignorer le warning spécifique concernant la fuite de mémoire avec KMeans sur Windows avec MKL
warnings.filterwarnings("ignore", message="KMeans is known to have a memory leak on Windows with MKL")
# ( 2 ) Créer un nuage de points pour visualiser les données
plt.figure(figsize=(8, 6))
plt.scatter(ages, weights, c='blue', marker='o', label='Données brutes' , s=250)
plt.title('Nuage de points des âges et des poids des étudiants')
plt.xlabel('Âge')
plt.ylabel('Poids')
plt.legend()
plt.grid(True)
plt.show()
# ( 3 ) Créer et ajuster le modèle K-means avec 3 clusters
kmeans = KMeans(n_clusters=3, n_init=10)
kmeans.fit(studentsData)
# ( 4 ) Obtenir les centres des clusters
centroids = kmeans.cluster_centers_
# ( 5 ) Obtenir les labels des clusters pour chaque point
labels = kmeans.labels_
# ( 6 ) Assigner des couleurs spécifiques à chaque cluster
colors = ['red', 'green', 'orange']
# ( 7 ) Visualiser les clusters obtenus avec des couleurs différentes
plt.figure(figsize=(8, 6))
for i in range(len(studentsData)):
plt.scatter(studentsData[i][0], studentsData[i][1], c=colors[labels[i]], marker='o', s=250)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', s=250, c='blue', label='Centres de cluster')
plt.title('Clusters obtenus avec K-means')
plt.xlabel('Âge')
plt.ylabel('Poids')
plt.legend()
plt.grid(True)
plt.show()
Après exécution, on obtient la figure des données brutes non traité avec l'algorithme K-Means et ensuite la figure des données traités avec l'algorithme de clustering K-Means là où on peut observer clairement les données divisées en trois groupes distingués par des couleurs différentes:
Younes Derfoufi
CRMEF OUJDA


